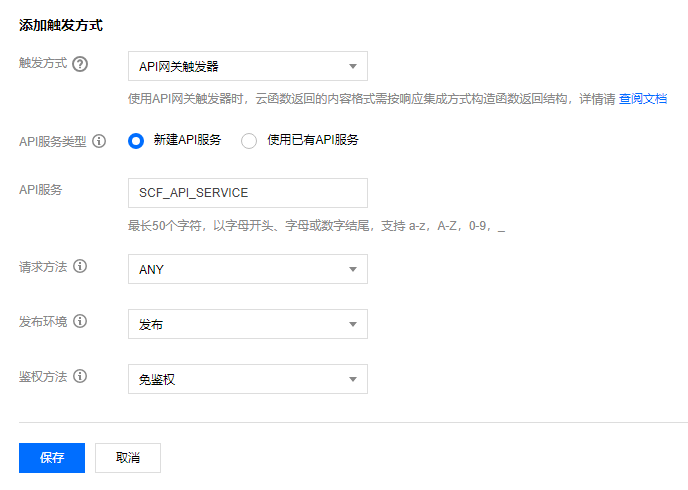
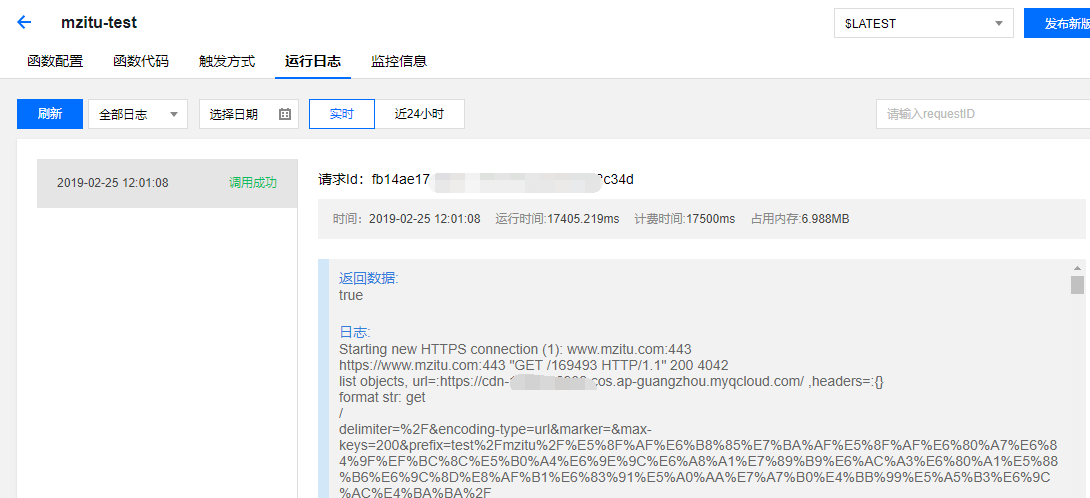
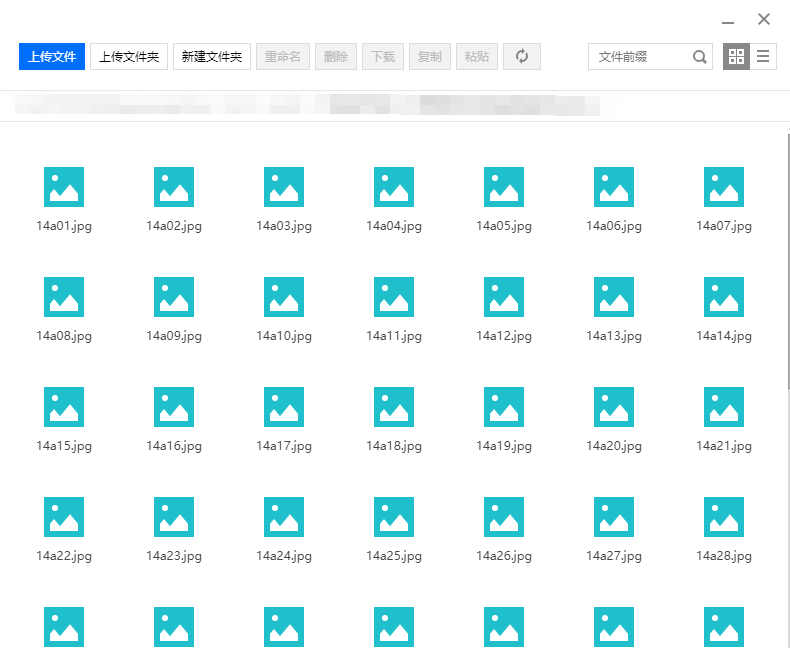
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| import requests, re, os
from contextlib import closing
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
from qcloud_cos import CosClientError
from qcloud_cos import CosServiceError
from bs4 import BeautifulSoup
BUCKET = os.environ.get('bucket')
PREFIX = os.environ.get('prefix', '/')
COS = CosS3Client(CosConfig(
Region=os.environ.get('region'),
Secret_id=os.environ.get('secret_id'),
Secret_key=os.environ.get('secret_key'),
Token=os.environ.get('token')
))
TMP = '/tmp/'
HEADERS = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
'Referer': 'https://www.xxx.com'
}
def download(downloadUrl, uploadPath):
with closing(requests.get(downloadUrl, stream=True, headers=HEADERS)) as response:
if response.status_code == 200:
filePath = TMP + os.path.basename(uploadPath)
with open(filePath, 'wb') as file:
for data in response.iter_content(1024):
file.write(data)
file.flush()
try:
COS.upload_file(
Bucket=BUCKET,
Key=PREFIX + uploadPath,
LocalFilePath=filePath
)
except (CosServiceError, CosClientError) as e:
print(e.get_resource_location())
os.remove(filePath)
def main_handler(event, context):
if not 'queryString' in event.keys() or not 'id' in event['queryString'].keys():
print('参数错误')
return False
url = 'https://www.xxx.com/%d' % int(event['queryString']['id'])
response = requests.get(url)
html = BeautifulSoup(response.text,'html.parser')
title = html.select('h2.main-title')[0].text
response = COS.list_objects(
Bucket=BUCKET,
Prefix=PREFIX + title + '/',
Delimiter='/',
MaxKeys=200
)
if 'Contents' in response.keys() and len(response['Contents']) == html.select('.pagenavi a:nth-last-child(2) span')[0].text:
print('已存在')
return True
next_url = url
while 1:
response = requests.get(next_url)
html = BeautifulSoup(response.text,'html.parser')
data = html.select('.main-image a')[0]
img_url = data.select('img')[0].attrs.get('src')
download(img_url, title + '/' + os.path.basename(img_url))
next_url = data.attrs.get('href')
if not url in next_url:
break
print('完成')
return True
|